Raster Font File Format
This topic details the font file format used by the lcd. object. The font file is a resource file that is added to your Tibbo BASIC/C project. Like all other resource files "attached" to your project, font files are accessible through the romfile. object. The use and interpretation of font file data, however, is the responsibility of the lcd.object; the romfile. object merely stores these files.
Tibbo font files have the "TRF" (Tibbo Raster Font) extension. The TRF file format was designed with the following considerations in mind:
- Ability to handle large character sets (such as those required for Chinese-language support). Hence, the use of 16-bit character codes.
- 16-bit character sets usually have large "gaps" (i.e., areas of unused codes). The TRF format offers an efficient way to define which characters are included into the font file and allows for very efficient character searching within the file.
- Support for proportional fonts. Hence, each character's width is individually defined.
- Support for fonts with anti-aliasing. Anti-aliasing is achieved by adjusting the "intensity" (brightness) of individual pixels. In an anti-aliased font, each pixel of a character bitmap is represented by 2 or more bits of data. Fonts without anti-aliasing just need 1 data bit/pixel because each pixel can only be ON or OFF. TiOS currently supports only fonts with 1 bit/pixel.
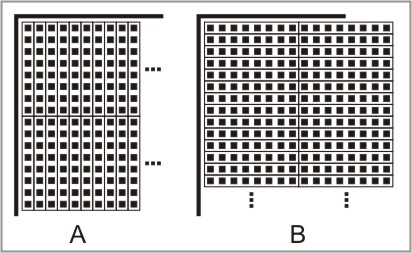
- Support for vertical and horizontal character bitmap encoding. Displays with lcd.bitsperpixel = 1, 2, or 4 pack 8, 4, or 2 pixels into a single byte of display memory. Problem is, some displays combine the pixels vertically (see drawing A below) and some horizontally (drawing B). The text output on such displays is more efficient if character bitmaps of the TRF file use the same direction of packing.
TRF File Format
The TRF file consists of four data areas:
|
Data area |
Description |
|
Header |
Contains various information such as the total number of characters in this font, character height, etc. Also contains the number of code groups in the code groups table (see below). |
|
Code groups table |
Contains descriptors of "code groups." Each code group contains information about a range of codes that has no "gaps" (i.e., unused codes in the middle). The font file can have as many code groups as necessary. |
|
Bitmap offset table |
Contains addresses (offsets) of all character bitmaps in the TRF file. In combination with the code groups table, provides a way to find the bitmap of any specific character. |
|
Bitmaps |
Contains all bitmaps of each character included into the font file. The width of each bitmap is defined individually and is stored together with the bitmap. |
Header Format
The header has a fixed length of 16 bytes and stores the following information:
|
Offset* |
Bytes |
Data |
Comment |
|
+0 |
2 |
Num_of_chars |
Total number of characters in this font file |
|
+2 |
1 |
Pixels_per_byte |
Modes 1, 2, and 3 are currently not supported; these modes are for anti-aliasing and will be supported in the future. |
|
+3 |
1 |
Orientation |
|
|
+4 |
1 |
Height |
Maximum character height in this font, in pixels. |
|
+5 |
9 |
<Reserved> |
Reserved for future use |
|
+14 |
2 |
Num_of_groups |
Number of entries in the code groups table |
*With respect to the beginning of the file
Code Groups Table
This table has a variable number of entries. This number is stored in the num_of_groups field of the header. Each code group represents a range of codes that contains no gaps (no unused character codes in the middle). For example, suppose that we have a font that only contains the characters "0"~"9" and "A"~"Z"; this font file will contain two groups of codes: 0030H through 0039H ("0"~"9") and 0041H through 005AH ("A"~"Z").
Each entry in the code groups table is 8 bytes long and has the following format:
|
Offset* |
Bytes |
Data |
Comment |
|
+0 |
2 |
Start_code |
The first code in the group |
|
+2 |
2 |
Num_codes |
Number of individual character codes in this group |
|
+4 |
4 |
Bitmap_addr_offset |
Address (that falls within the bitmap offset table and is given with respect to the beginning of the file) at which the address of the bitmap of the first character in the code group is stored. |
* With respect to the beginning of a particular table entry
For the above example, the code groups table will have two entries:
|
Start_code |
Num_codes |
Bitmap_offset |
|
0030H |
000AH |
00000020H |
|
0041H |
001AH |
00000048H |
Here is how the above data was calculated. The start codes are obvious. Group one starts with code 0030H because this is the "0" character code. The second group starts with the "A" character code. It is also easy to fill out the number of codes in each group: 10 (000AH) for "0"~"9" and "A"~"Z" represented by 26 (001AH). The bitmap_addr_offset calculation is explained in the next section.
Bitmap Offset Table
This table has the same number of entries as the total number of characters included in the font file. Each entry consists of one field — a 32-bit offset of a particular bitmap with respect to the beginning of the font file. Now you can see how we were able to calculate the data for the bitmap_addr_offset field of the code groups table. The header of the font file has a fixed length of 16 bytes. There are two code groups in our example, so the code groups table occupies 8 x 2 = 16 bytes. This means that the bitmap offset table starts from address 16 + 16 = 32 (0020H). Hence, the first entry in the code groups table points at address 0020H. The first code group contains 10 characters ("0"~"9"). These will "occupy" 10 entries in the bitmap offset table, which results in 10 x 4 = 40 bytes. Hence, the bitmap_addr_offset field for the second code group is set to 32 + 40 = 72 (0048H).
Bitmaps
Each bitmap starts with a single byte that encodes the width of the bitmap in pixels, followed by the necessary number of bytes representing this bitmap. Depending on the pixels_per_byte field of the header, each byte of data may encode just one or several pixels. Additionally, when using more than 1 pixel-per-byte encoding, the orientation field of the header defines whether pixels are combined horizontally or vertically.
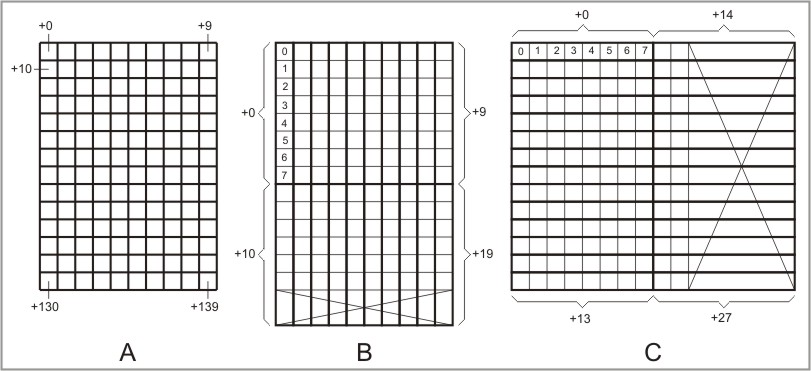
The drawings below illustrate how character bitmaps are stored in the font file. As an example, characters of 10x14 size (in pixels) are used. Drawing A is for one pixel/byte encoding, drawing B is for 8 pixels/byte with vertical orientation, and C is for 8 pixels/byte with horizontal orientation. Notice that for cases B and C, a portion of some bytes used to store the bitmaps is unused. Offsets of bytes relative to the beginning of the bitmap data are shown with a "+" sign.
Bitmap A takes 140 bytes. The first byte (+0) represents the pixel at the top left corner of the bitmap. Subsequent bytes represent all other pixels and the order is "left-to-right, top-to-bottom."
Bitmap B takes 20 bytes. The first byte encodes 8 vertically arranged pixels at the top left corner of the bitmap. Subsequent bytes represent all other pixel groups and the order is "left-to-right, top-to-bottom." There are two rows of bytes, and bits 6 and 7 of each byte in the second row are unused.
Bitmap C takes 28 bytes. The first byte encodes 8 horizontally arranged pixels at the top left corner of the bitmap. Subsequent bytes represent all other pixel groups and the order is "top-to-bottom, left-to-right." There are two columns of bytes, and bits 2~7 of each byte in the second column are unused.
Searching for a Character Bitmap
Here is how a target character bitmap is found within the font file. Again, we are using the example of the font file that contains the characters "0"~"9" and "A"~"Z."
Suppose we need to find the bitmap of character "C" (code 0043H). First, we need to see to which code group code 004AH belongs. We read the num_of_groups field of the header to find out how many code groups are contained in the font file. The field tells us that there are two groups.
Next, we start reading the code groups table (located at file offset +00000010H), entry by entry, in order to determine to which code group the target character belongs. The first group starts from code 0030H and contains 10 characters. Therefore, the target character doesn't belong to it. The second group starts from code 0041H and contains 26 characters. The target code is 0043H. Therefore, target character belongs to this second group.
Next, we find the corresponding entry in the bitmap offset table. For this, we do a simple calculation:
bitmap_offset + (desired_code - start_code) * 4: 00000048H + (0043H - 0041H) * 4 = 00000050H.
Next, we read a 32-bit value at file offset 00000050H. This will tell us the file offset at which the target bitmap is stored.
At this file offset, the first byte will be the width of the bitmap in pixels. Based on this width and also the height, pixels_per_byte and orientation fields of the header, we can calculate the number of bytes in the bitmap. For example, suppose that height = 14, pixels_per_byte = 0 (8 pixels/byte), and orientation = 0 (pixels are grouped vertically). Also, let's suppose that the width of the target character is 10 pixels. In this case, the bitmap will occupy 20 bytes, as shown in drawing B above. Two bits of each byte in the second byte row will be unused.